在过去的几年里,人工智能(AI)一直是媒体大肆炒作的热点话题。机器学习、深度学习和人工智能都出现在不计其数的文章中,而这些文章通常都发表于非技术出版物。我们的未来被描绘成拥有智能聊天机器人、自动驾驶汽车和虚拟助手,这一未来有时被渲染成可怕的景象,有时则被描绘为乌托邦,人类的工作将十分稀少,大部分经济活动都由机器人或人工智能体(AI agent)来完成。对于未来或当前的机器学习从业者来说,重要的是能够从噪声中识别出信号,从而在过度炒作的新闻稿中发现改变世界的重大进展。
深度学习发展由来
深度学习思想来源于人类处理视觉信息方式,人类视觉系统是这个世界上最为神奇的一个系统。
1981年的诺贝尔医学奖,颁发给了David Hubel(出生于加拿大的美国神经生物学家)和TorstenWiesel,以及Roger Sperry。前两位的主要贡献,是“发现了视觉系统的信息处理”:可视皮层是分级的: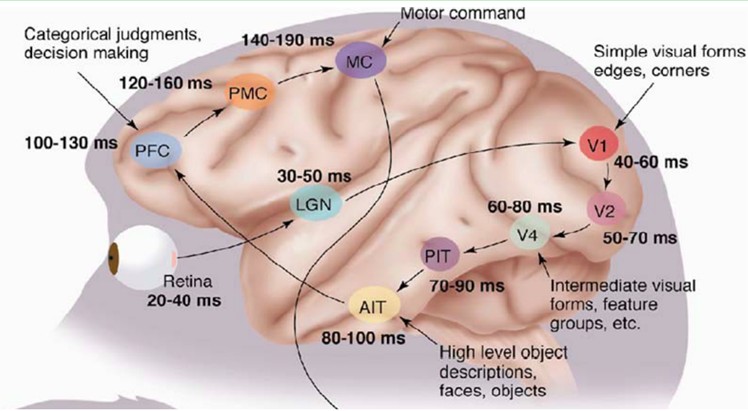
1958 年,David Hubel 和Torsten Wiesel在JohnHopkins University,研究瞳孔区域与大脑皮层神经元的对应关系。他们在猫的后脑头骨上,开了一个3 毫米的小洞,向洞里插入电极,测量神经元的活跃程度。然后,他们在小猫的眼前,展现各种形状、各种亮度的物体。并且,在展现每一件物体时,还改变物体放置的位置和角度。他们期望通过这个办法,让小猫瞳孔感受不同类型、不同强弱的刺激。之所以做这个试验,目的是去证明一个猜测。位于后脑皮层的不同视觉神经元,与瞳孔所受刺激之间,存在某种对应关系。一旦瞳孔受到某一种刺激,后脑皮层的某一部分神经元就会活跃。经历了很多天反复的枯燥的试验,同时牺牲了若干只可怜的小猫,David Hubel 和Torsten Wiesel 发现了一种被称为“方向选择性细胞(Orientation Selective Cell)”的神经元细胞。当瞳孔发现了眼前的物体的边缘,而且这个边缘指向某个方向时,这种神经元细胞就会活跃。这个发现激发了人们对于神经系统的进一步思考。神经-中枢-大脑的工作过程,或许是一个不断迭代、不断抽象的过程。这里的关键词有两个,一个是抽象,一个是迭代。从原始信号,做低级抽象,逐渐向高级抽象迭代。人类的逻辑思维,经常使用高度抽象的概念。例如,从原始信号摄入开始(瞳孔摄入像素 Pixels),接着做初步处理(大脑皮层某些细胞发现边缘和方向),然后抽象(大脑判定,眼前的物体的形状,是圆形的),然后进一步抽象(大脑进一步判定该物体是只气球)。
这个生理学的发现,促成了计算机人工智能,在四十年后的突破性发展。
总的来说,人的视觉系统的信息处理是分级的。从低级的V1区提取边缘特征,再到V2区的形状或者目标的部分等,再到更高层,整个目标、目标的行为等。也就是说高层的特征是低层特征的组合,从低层到高层的特征表示越来越抽象,越来越能表现语义或者意图。而抽象层面越高,存在的可能猜测就越少,就越利于分类。例如,单词集合和句子的对应是多对一的,句子和语义的对应又是多对一的,语义和意图的对应还是多对一的,这是个层级体系。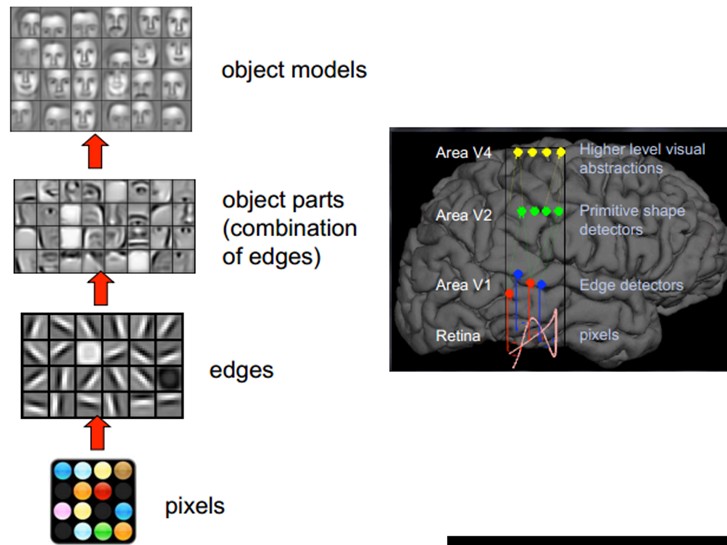
深度学习是机器学习的分支
深度学习其动机在于建立可以模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如,图像、声音和文本。深度学习之所以被称为“深度”,是因为之前的机器学习方法都是浅层学习。深度学习可以简单理解为传统神经网络(Neural Network)的发展。大约二三十年前,神经网络曾经是机器学习领域特别热门的一个方向,这种基于统计的机器学习方法比起过去基于人工规则的专家系统,在很多方面显示出优越性。深度学习与传统的神经网络之间有相同的地方,采用了与神经网络相似的分层结构:系统是一个包括输入层、隐层(可单层、可多层)、输出层的多层网络,只有相邻层节点(单元)之间有连接,而同一层以及跨层节点之间相互无连接。这种分层结构,比较接近人类大脑的结构(但不得不说,实际上相差还是很远的,考虑到人脑是个异常复杂的结构,很多机理我们目前都是未知的)。
人类从经验中学习知识。经验越丰富,可以学到的知识越多。在人工智能 (AI) 学科的深度学习领域,这一原理也相通,即由人工智能软硬件提供动力支持的机器从经验中学习知识。用于机器从中学习知识的这些经验由机器采集的数据确定,数据的数量和质量决定了机器可以学到的知识量。
深度学习(Deep Learning)是机器学习(Machine Learning)的一个分支,是一种试图使用包含复杂结构或由多重非线性变换构成的多个处理层对数据进行高层抽象的算法。 深度学习是机器学习中一种基于对数据进行表征学习的算法,至今已有数种深度学习框架,如卷积神经网络和深度置信网络和递归神经网络等已被应用在计算机视觉、语音识别、自然语言处理、音频识别与生物信息学等领域并获取了极好的效果。
许多传统机器学习算法学习能力有限,数据量的增加并不能持续增加学到的知识总量,而深度学习系统可以通过访问更多数据来提升性能,即“更多经验”的机器代名词。机器通过深度学习获得足够经验后,即可用于特定的任务,如驾驶汽车、识别田地作物间的杂草、确诊疾病、检测机器故障等。
深度学习是一个数学问题
机器学习和数学,是深度学习的一体两面。
机器学习是深度学习的方法论,数学是其背后的理论支撑。
其实每一种算法,究其根本,都是一种数学表达。无论是机器学习,还是深度学习,都是试图找到一个函数,这个函数可以简单,可以复杂,函数的表达并不重要,只是一个工具,重要的是这个函数能够尽可能准确的拟合出输入数据和输出结果间的关系。就像我们在各个任务中做的那样,比如语音识别、图像识别、下围棋,人机问答系统:
这就是机器学习要做到的事,找到一个数学表达,即上述例子中的函数f。
而深度学习的魅力在于,它的数学表达特别的强!
深度学习的强大是有数学原理支撑的,这个原理叫做“万能近似定理”(Universal approximation theorem)。这个定理的道理很简单 —— 神经网络可以拟合任何函数,不管这个函数的表达是多么的复杂。
因为这个定理,深度学习在拟合函数这一方面的能力十分强大、暴力和神秘。
深度学习是一个黑箱
黑箱的意思是,深度学习的中间过程不可知,深度学习产生的结果不可控。
一方面,我们比较难知道网络具体在做些什么;另一方面,我们很难解释神经网络在解决问题的时候,为什么要这么做,为什么有效果。
在传统的机器学习中,算法的结构大多充满了逻辑,这种结构可以被人分析,最终抽象为某种流程图或者一个代数上的公式,最典型的比如决策树,具有非常高的可解释性。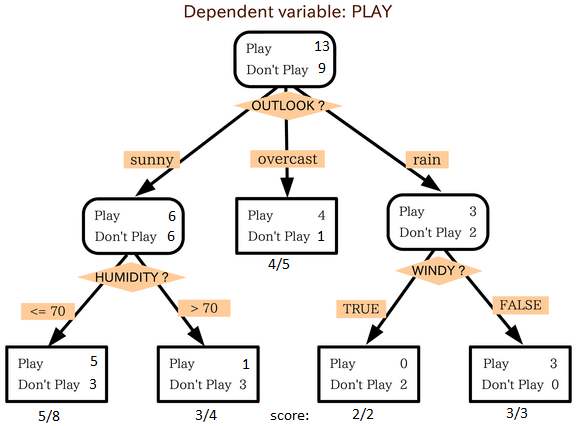
到了深度学习,这样子的直观就不见了。简单来说,深度学习的工作原理,是通过一层层神经网络,使得输入的信息在经过每一层时,都做一个数学拟合,这样每一层都提供了一个函数。因为深度学习有好多层,通过这每一层的函数的叠加,深度学习网络的输出就无限逼近目标输出了。这样一种“万能近似”,很多时候是输入和输出在数值上的一种耦合,而不是真的找到了一种代数上的表达式。当我们在说”拟合“、”函数“这一类词的时候,你或许认为我们会像写公式一样把输入和输出之间的关系列在黑板上。
所以,很多时候,你的深度学习网络能很好的完成你的任务,可是你并不知道网络学习到了什么,也不知道网络为什么做出了特定的选择。知其然而不知其所以然,这可以看作是深度学习的常态,也是深度学习工作中的一大挑战。
深度学习的优点和缺点

优点1:学习能力强
从结果来看,深度学习的表现非常好,他的学习能力非常强。
优点2:覆盖范围广,适应性好
深度学习的神经网络层数很多,宽度很广,理论上可以映射到任意函数,所以能解决很复杂的问题。
优点3:数据驱动,上限高
深度学习高度依赖数据,数据量越大,他的表现就越好。在图像识别、面部识别、NLP 等部分任务甚至已经超过了人类的表现。同时还可以通过调参进一步提高他的上限。
优点4:可移植性好
由于深度学习的优异表现,有很多框架可以使用,例如 TensorFlow、Pytorch。这些框架可以兼容很多平台。
缺点1:计算量大,便携性差
深度学习需要大量的数据很大量的算力,所以成本很高。并且现在很多应用还不适合在移动设备上使用。目前已经有很多公司和团队在研发针对便携设备的芯片。这个问题未来会得到解决。
缺点2:硬件需求高
深度学习对算力要求很高,普通的 CPU 已经无法满足深度学习的要求。主流的算力都是使用 GPU 和 TPU,所以对于硬件的要求很高,成本也很高。
缺点3:模型设计复杂
深度学习的模型设计非常复杂,需要投入大量的人力物力和时间来开发新的算法和模型。大部分人只能使用现成的模型。
缺点4:没有”人性”,容易存在偏见
由于深度学习依赖数据,并且可解释性不高。在训练数据不平衡的情况下会出现性别歧视、种族歧视等问题。
四种典型的深度学习算法

卷积神经网络 — CNN
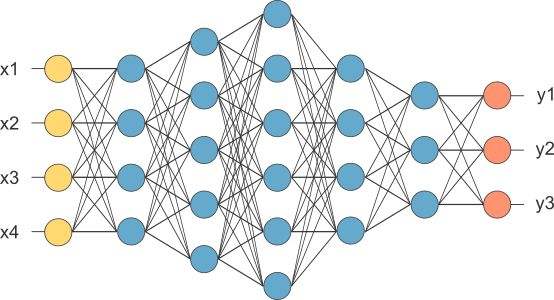
CNN 的价值:
能够将大数据量的图片有效的降维成小数据量(并不影响结果)
能够保留图片的特征,类似人类的视觉原理
CNN 的基本原理:
卷积层 — 主要作用是保留图片的特征
池化层 — 主要作用是把数据降维,可以有效的避免过拟合
全连接层 — 根据不同任务输出我们想要的结果
CNN 的实际应用:
1、 图片分类、检索
2、 目标定位检测
3、 目标分割
4、 人脸识别
5、 骨骼识别
循环神经网络 — RNN
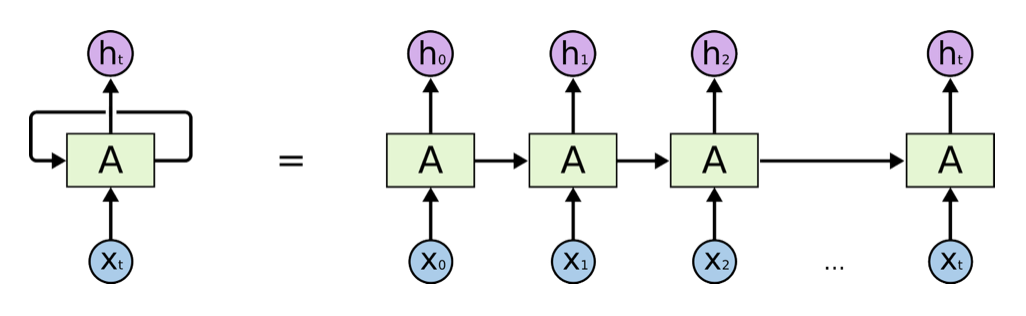
RNN是一种能有效的处理序列数据的算法。比如:文章内容、语音音频、股票价格走势等等。
之所以他能处理序列数据,是因为在序列中前面的输入也会影响到后面的输出,相当于有了“记忆功能”。但是 RNN 存在严重的短期记忆问题,长期的数据影响很小(哪怕他是重要的信息)。
于是基于RNN 出现了LSTM和GRU等变种算法。这些变种算法主要有几个特点:
1、 长期信息可以有效的保留
2、 挑选重要信息保留,不重要的信息会选择“遗忘”
RNN 几个典型的应用如下:
1、 文本生成
2、 语音识别
3、 机器翻译
4、 生成图像描述
5、 视频标记
生成对抗网络 — GANs
假设一个城市治安混乱,很快,这个城市里就会出现无数的小偷。在这些小偷中,有的可能是盗窃高手,有的可能毫无技术可言。假如这个城市开始整饬其治安,突然开展一场打击犯罪的「运动」,警察们开始恢复城市中的巡逻,很快,一批「学艺不精」的小偷就被捉住了。之所以捉住的是那些没有技术含量的小偷,是因为警察们的技术也不行了,在捉住一批低端小偷后,城市的治安水平变得怎样倒还不好说,但很明显,城市里小偷们的平均水平已经大大提高了。
警察们开始继续训练自己的破案技术,开始抓住那些越来越狡猾的小偷。随着这些职业惯犯们的落网,警察们也练就了特别的本事,他们能很快能从一群人中发现可疑人员,于是上前盘查,并最终逮捕嫌犯;小偷们的日子也不好过了,因为警察们的水平大大提高,如果还想以前那样表现得鬼鬼祟祟,那么很快就会被警察捉住。为了避免被捕,小偷们努力表现得不那么「可疑」,而魔高一尺、道高一丈,警察也在不断提高自己的水平,争取将小偷和无辜的普通群众区分开。随着警察和小偷之间的这种「交流」与「切磋」,小偷们都变得非常谨慎,他们有着极高的偷窃技巧,表现得跟普通群众一模一样,而警察们都练就了「火眼金睛」,一旦发现可疑人员,就能马上发现并及时控制 — — 最终,我们同时得到了最强的小偷和最强的警察。
深度强化学习 — RL
强化学习算法的思路非常简单,以游戏为例,如果在游戏中采取某种策略可以取得较高的得分,那么就进一步「强化」这种策略,以期继续取得较好的结果。这种策略与日常生活中的各种「绩效奖励」非常类似。我们平时也常常用这样的策略来提高自己的游戏水平。
在Flappy bird这个游戏中,我们需要简单的点击操作来控制小鸟,躲过各种水管,飞的越远越好,因为飞的越远就能获得更高的积分奖励。
这就是一个典型的强化学习场景:
- 机器有一个明确的小鸟角色 — — 代理
- 需要控制小鸟飞的更远 — — 目标
- 整个游戏过程中需要躲避各种水管 — — 环境
- 躲避水管的方法是让小鸟用力飞一下 — — 行动
- 飞的越远,就会获得越多的积分 — — 奖励
 Flappy bird
Flappy bird
你会发现,强化学习和监督学习、无监督学习 最大的不同就是不需要大量的“数据喂养”。而是通过自己不停的尝试来学会某些技能。
总结
深度学习属于机器学习的范畴,深度学习可以说是在传统神经网络基础上的升级,约等于神经网络。
深度学习和传统机器学习在数据预处理上都是类似的。核心差别在特征提取环节,深度学习由机器自己完成特征提取,不需要人工提取。
